Practical Internship
February 2025 – June 2025
Overview
As part of our 3rd year of study we had to find and complete a practical internship with a company. By working in a real world environment with real, often imperfect data we, as students, have learned not only how to act in a professional environment but also how to pivot and adapt solutions to the available data and resources. In order to provide value we have to apply data-driven solutions in various fields. Additionally, a big part of the challenge is becoming familiar with the domain of the project in order to find the most appropriate solutions.
Following the advice of Dr. Alican Noyan, I started applying and sending open applications to companies with headquarters in the High Tech Campus in Eindhoven. One of the open applications was sent towards Eurofins EAG, a material science lab. My previous University experience studying robotics alongside my experience working with NPEC and Specifix, made me very interested in the possibility of finding data-driven solutions for material science applications, combining machine learning with both physics and chemistry. The interview presented the opportunity of working with SEM/EDX datasets in order to classify particles from samples, which I was intrigued to research and find out more about.
Datasets
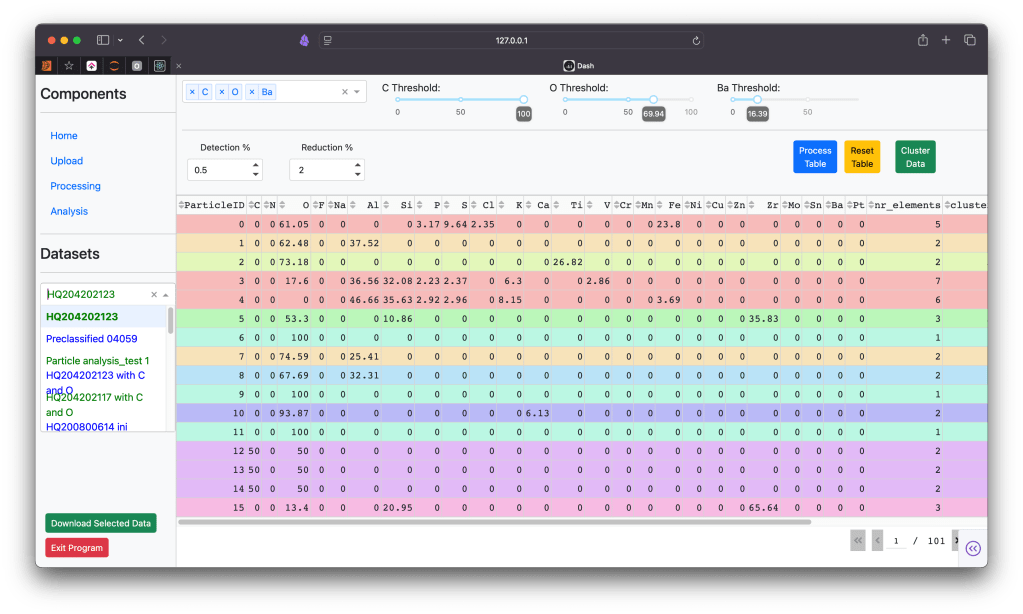
Each row in the dataset represents the unified results for individual particles. The columns consist of physical and chemical properties of particles.
Physical properties include:
| Area (μm²) | Aspect Ratio | Breadth (μm) | Direction (°) | ECD (μm) | Length (μm) | Perimeter (μm) | Shape |
| Area of the particle | Aspect Ratio of bounding box | Width of bounding box | Angle of Electron Beam | Equivalent Circular Diameter | Length of bounding box | Perimeter of Bounding Box | A quantified approximation to the shape of the feature |
Chemical properties include:
| C Wt% | N Wt% | O Wt% | F Wt% | … | Mg Wt% | Al Wt% | Si Wt% | P Wt% |
| Carbon Weight Percent | Nitrogen Weight Percent | Oxygen Weight Percent | Fluoride Weight Percent | All elements of the periodic table w/o H, He, Li | Magnesium Weight Percent | Aluminum Weight Percent | Silicon Weight Percent | Phosphorous Weight Percent |
These dataset are all tied to samples sent in by customers. The data comes from the SEM/EDX process and is first ran through the AZTEC software suite for preliminary analysis. From then on everything is done to order. Customers can request different analyses, for example: the number of steel particles per mm2, checking for oxidation, contamination, etc. All of these requests can be interpreted as counting and classifying a big number of particles, depending on the sample and the measurement area, process which is being done manually.
Approach
Initially it seemed like a basic classification problem where we have features and classes to train a multi-class model on. Unfortunately, the reality is that while many datasets had been manually labelled, the data storage solution at Eurofins EAG is not intended for long term storage of client data, especially since these labelled datasets are a preliminary stage of a final report that is handed in.
This changed the perspective of the project from a supervised to an unsupervised machine learning problem, which has different challenges. This discovery was made in the initial weeks of the project, while in the process of understanding and exploring the data.
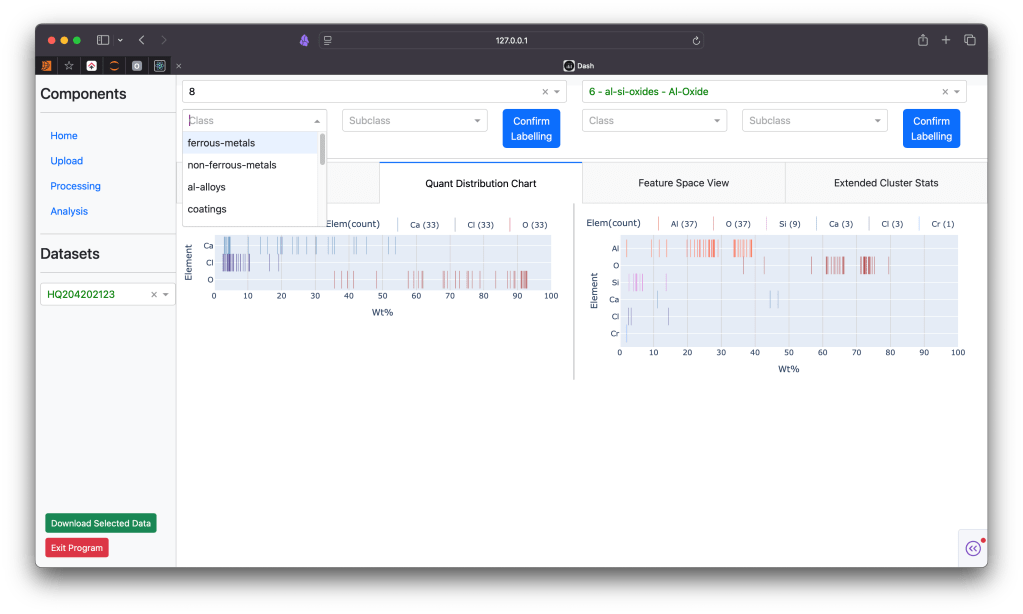
As a solution I arrived at the idea of creating a labelling tool aided by clustering algorithms. This tool also helps scientists perform preliminary cleaning of the data, analyze the found clusters and label entire datasets with ease.
In the long term, this speeds up the labelling process. Additionally with a more standardized approach to labelling, enough data can be gathered to train a classification model based either on the chemical composition of particles or on the trained parametric UMAP model.
Results